实战:requests+BeautifulSoup实现静态爬取
静态网页是指一次性加载所有内容的网页,爬虫一次请求便能得到所有信息,对爬虫非常友好。
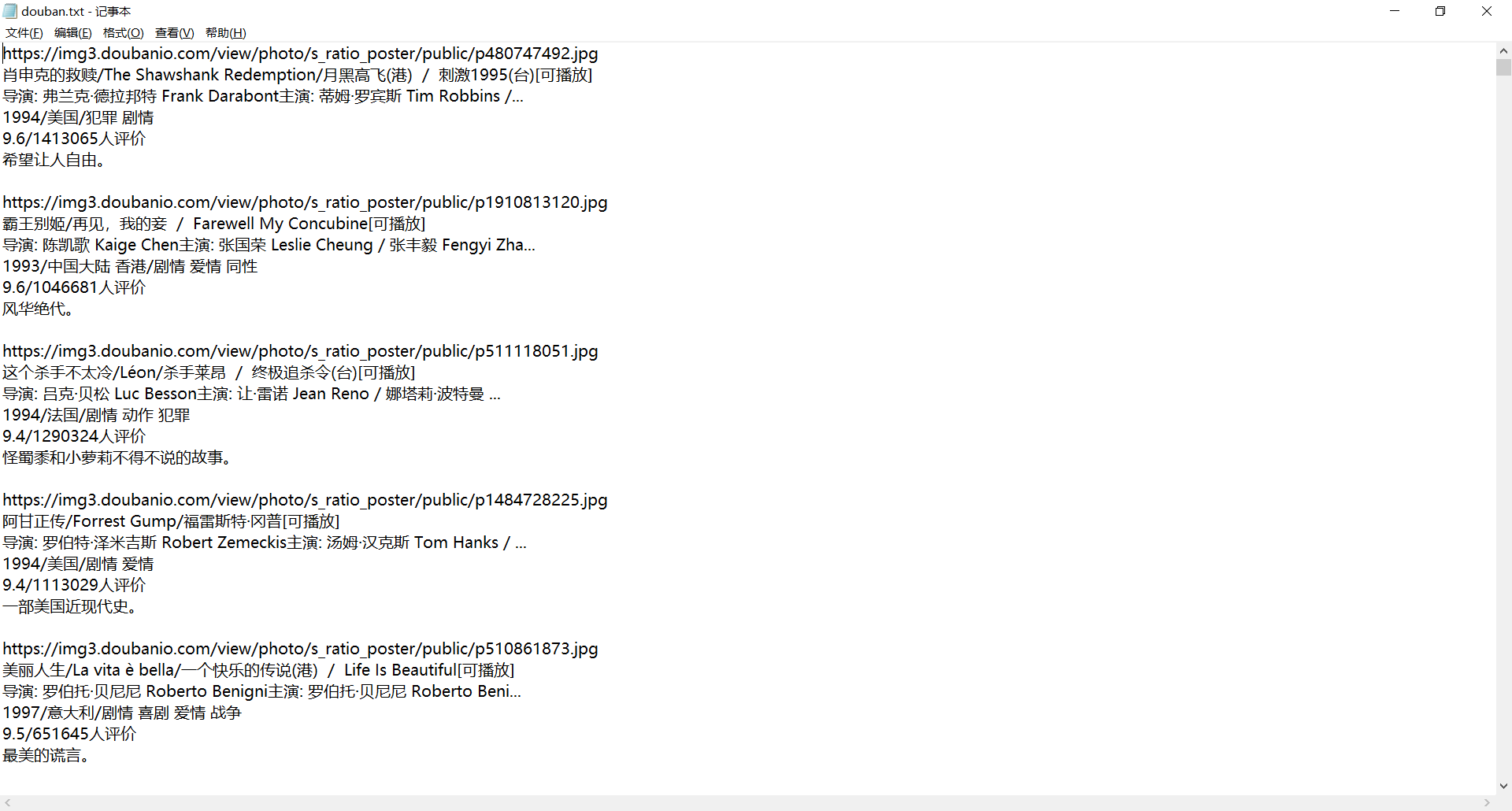
豆瓣top250电影信息爬取
网站为:https://movie.douban.com/top250
1 | 打开F12/右键检查第一个电影,分析源码先,发现每个<li>标签就对应着一个电影的信息。 |
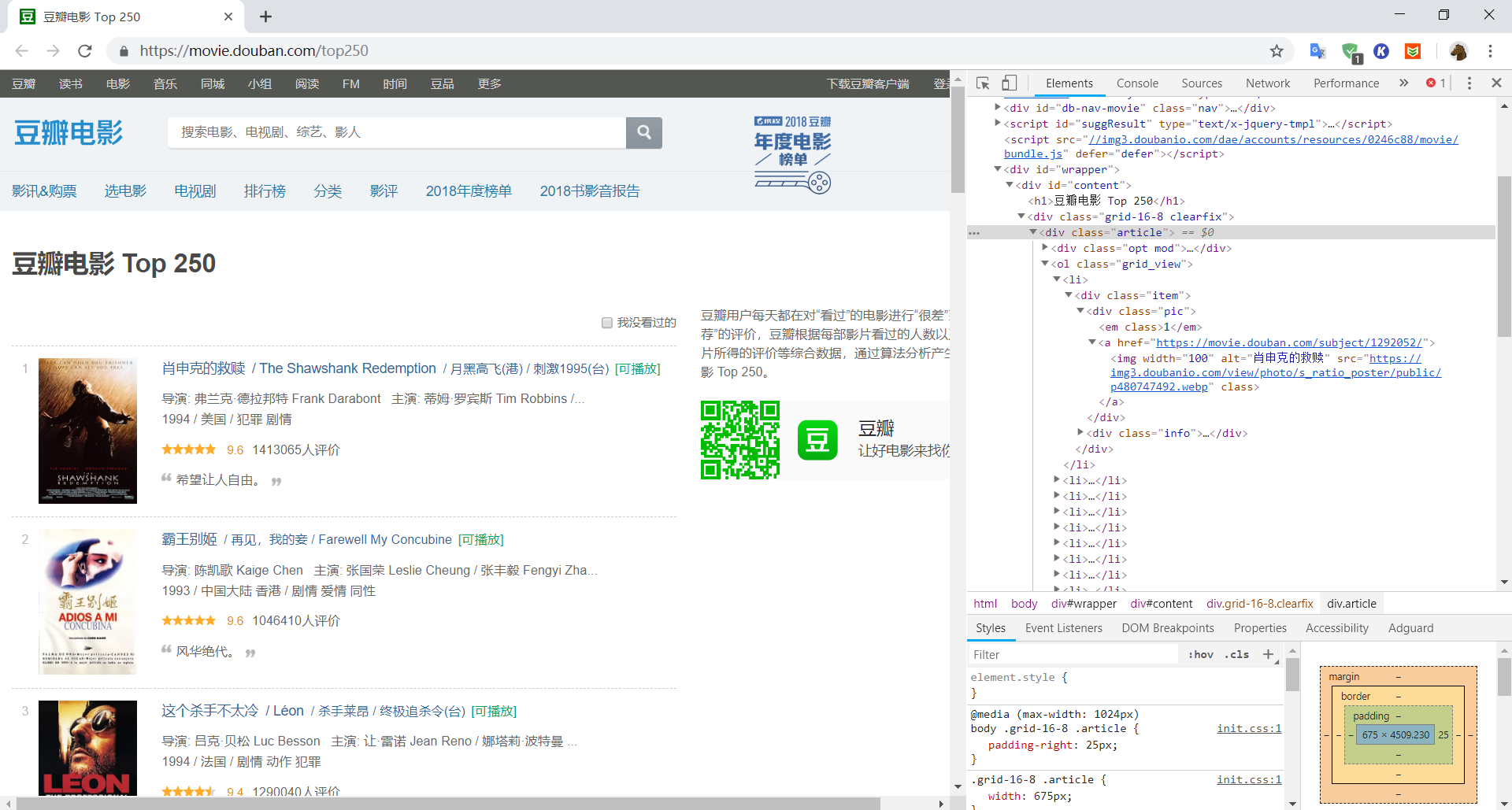
1 | 我们来爬取每部电影的图片,名称,导演演员,类型,评分,和它的一句话总结,继续对<li>标签进行分析,又发现信息又在<div class="info">标签里,而这标签只存在于<li>标签中,其它地方不存在,这样可以用find_all()方法把他们全部分离出来。这里不选择<li>标签是它没有唯一性,电影以外的内容也有<li>标签。 |
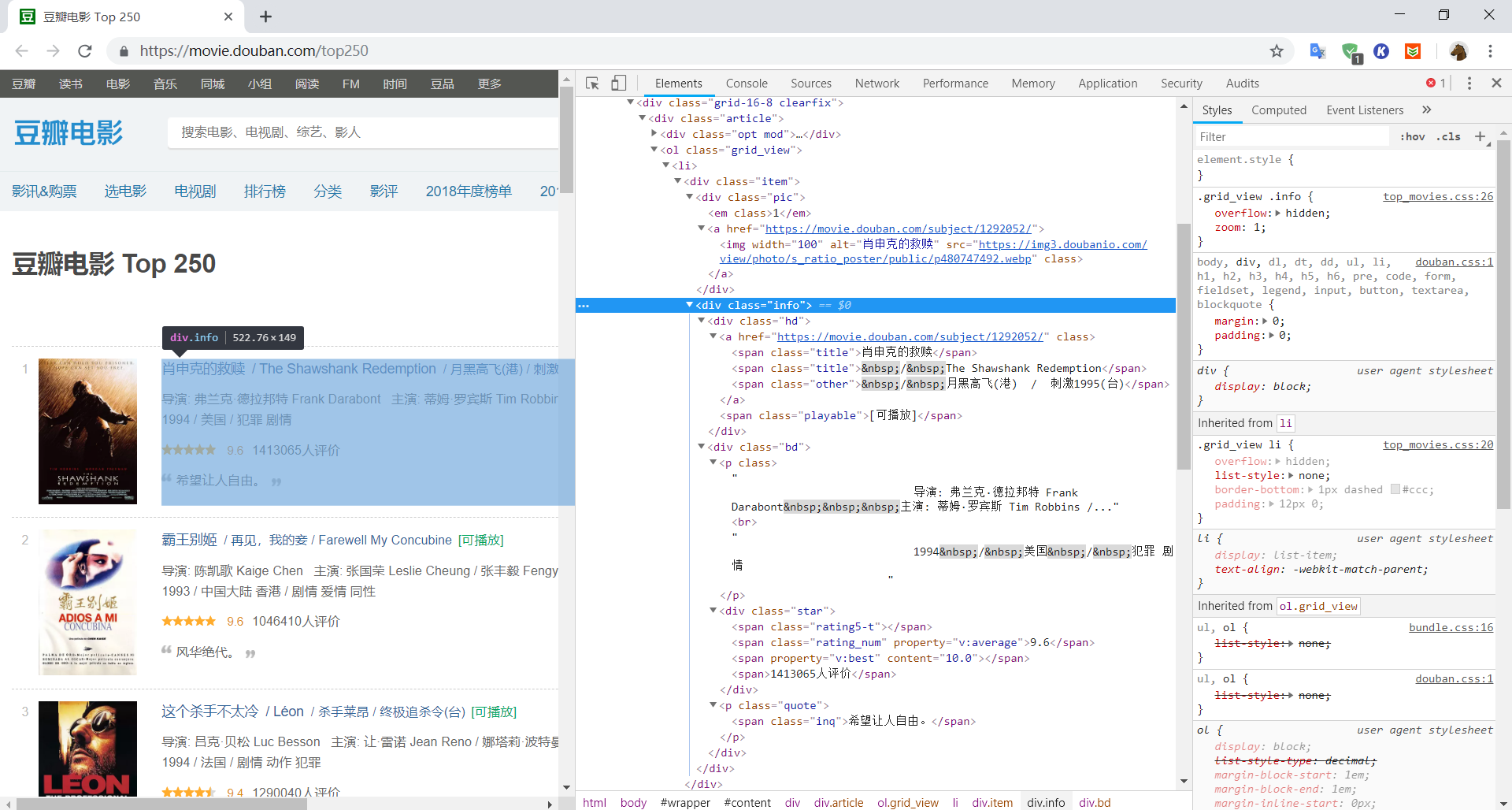
1 | 布置好伪装后就可一开始根据每个<div class="info">标签进行信息筛选了: |
1 | url = 'https://movie.douban.com/top250' |
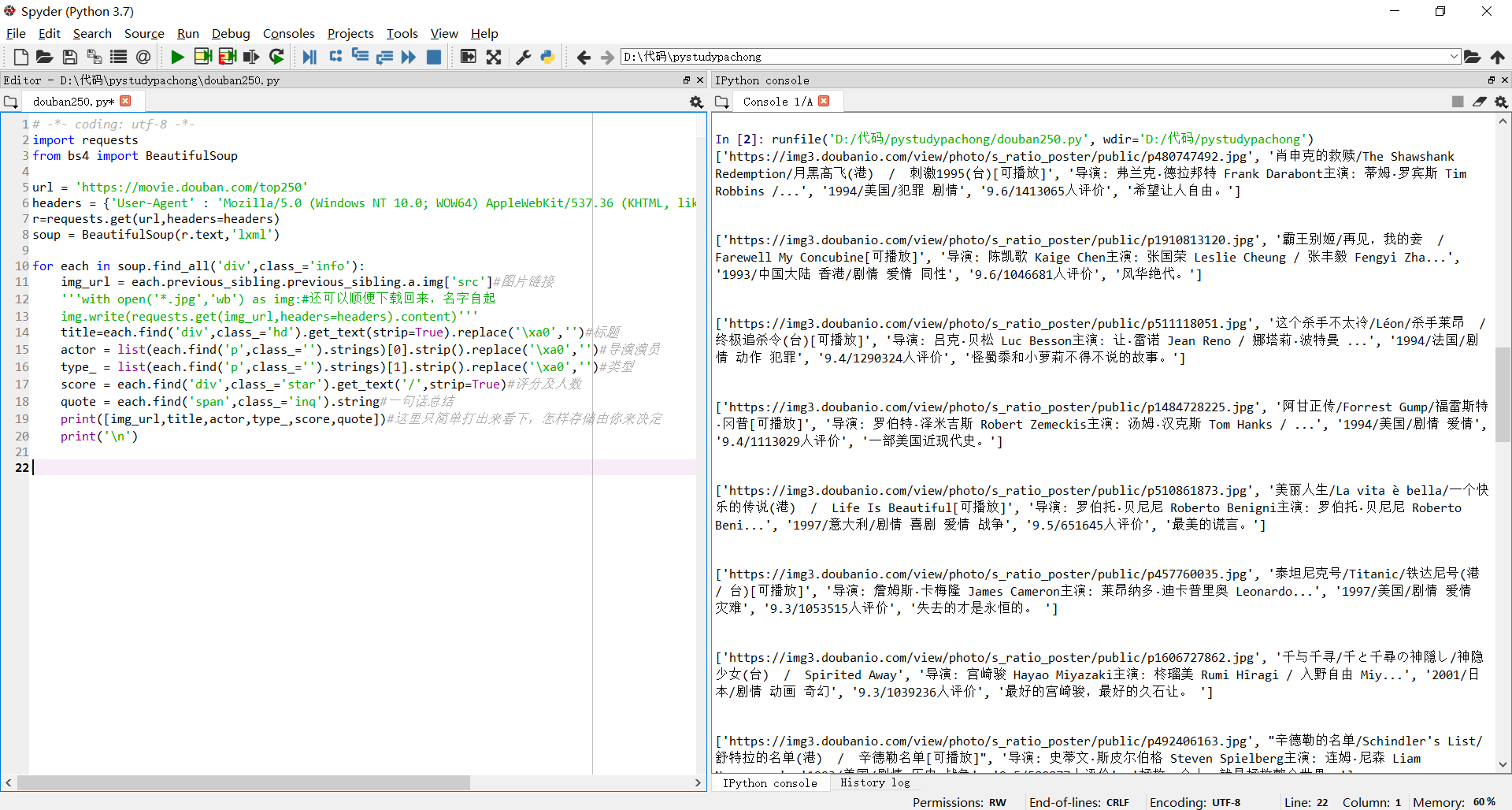
但是这样只有25部电影, ‘https://movie.douban.com/top250' 指向第一页,我们现在只爬了一页,其实还有9页还没爬啊,这是就要构造网址了。
我们点到第二页,发现网址变成了 https://movie.douban.com/top2?start=25&filter= ,第三页start条件值变成50,我们可以得出结论,每下一页,start条件值就加25。第一页start=0,第二页start=25…..第十页start=225。这样就可以循环构造网页并爬取了.
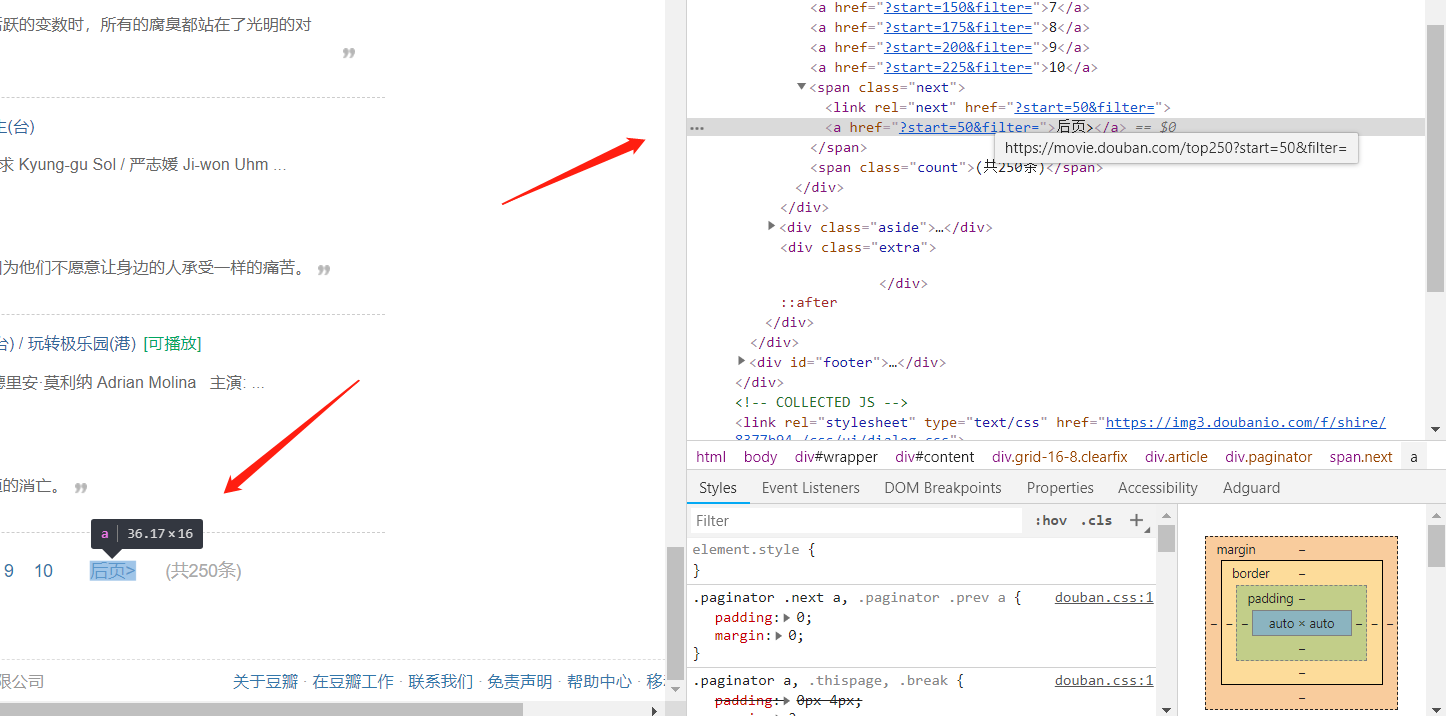
另一种思路:网页不是有下一页的按钮吗,右键检查一下,发现它已经包含了要构造的部分了,是一个属性值,提取出来接到原网址上即得到下一页的网址,这样能完全爬取所有页数,不用像上面一样设置循环次数。
1 | # -*- coding: utf-8 -*- |