动态爬取解决方案 之 手动分析
动态的标志
进入一个网页,鼠标到处点,滑轮上下滚,各种框框各种信息都蹦出来了,但是网页链接没变过,网页也没重新刷新过
比如:逛网页版的网易云音乐的评论时,无论评论翻到第几页,网址也不会改变;逛知乎时,鼠标不停往下滚,只要下面还有回答,就会不断的加载出来,同样网址也不会改变
类似这样能不转跳不刷新就能加载新信息的网页,就是用了动态加载。
分析什么
首先记住——所有信息在理论上都可以通过请求(链接)获得
然后记住——有些请求需要提交参数,检查headers什么的来防爬
附加一点——大多数动态加载的信息,通常都是json数据
有了这些指引提示我们就能描绘出大概的分析思路
- 首先我们要找到json数据请求链接,通过F12捉包获得,这种包属于xhr或js里
- 然后我们通过分析多个json数据的请求链接的参数,规律,推出所有链接的结构
- 如果json数据是一个post包,我们还要分析要post的参数的内容,规律(加密的另谈)
- 分析服务器是否检查请求的headers,如是,需要哪些额外headers(指user-agent外)
完成以上四步通常就能获得目标json数据,剩下的就是分析json数据本身,把目标提取出来
引导实例
以某宝为例,随便搜一个商品进去。打开F12,换到Network捉js的包,点到评论那里,很快就弹出很多个包,逐个查看其response,很快就确定了目标包,然后评论换页,捉多几个供链接分析用。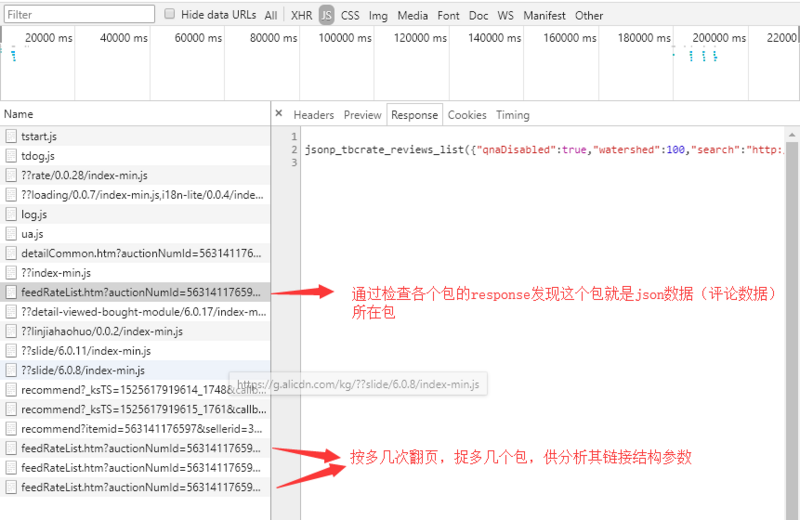
这是一个包的请求链接
通过对比刚才捉到的多个包的链接,和多次试验性发送请求,我们可以分析出链接结构——ua(包括ua)之后参数是不影响请求结果的,currentPageNum是评论页数,auctionNumId是商品id,userNumId可以不要,这样就足以构造所有json数据的请求链接,至于一些决定排序的参数这里就不再多分析。
多次试验后发现这个请求链接不需要提交数据,headers加个user-agent就可以返回数据
但是taobao返回的json数据有坑,注意一下
然后提取json数据,这样动态问题就解决了,可以完整的写出爬虫。jd评价的爬取和淘宝类似。
1 | import requests |

